Over the last few weeks, I’ve been in the process of relearning C++. Of course, saying that I am “relearning” is perhaps giving me too much credit, as it has been almost fifteen years since my first attempt at mastering the language. While it shares a good deal of syntax with other languages I’m more familiar with, I might as well be learning it for the first time. Although my previous programming experience has thus far been of very little use when suffering from linker errors or trying to track down memory leaks, it has given me an interesting perspective on my current endeavor. I’ve been programming (or attempting to) in one way or another since I was in elementary school. Starting with GW-BASIC, I slowly made my way to Visual Basic, C++, JavaScript, ActionScript 1, ActionScript 3, Haxe, and now back to C++ again. Most of these transitions, like my current one, largely involved starting from scratch. My fifth-grade self would probably be a bit sad to learn that the BEEP command that he managed to overuse in every program he ever wrote wouldn’t be of much use by the time he got to high school.
Learning a new programming language is generally not a purely iterative process. Even closely related languages have their own idiosyncrasies that don’t translate back and forth. This does not, however, mean that you can simply approach a new language as a blank slate. In fact, unlearning your old approaches is often the most difficult part of picking up a new language (particularly if you’ve managed to pick up some bad coding habits along the way). As such, it should come as no surprise that code, like any text, can say a lot about the people, organizations, and technologies that were involved in its creation.
Code is often a difficult object to approach from a humanistic perspective. In some cases, scholars have approached code as if it were simply a piece of literature, generally coming to the conclusion that code makes for very poor literature (Kücklich, 2003). More often, however, computer code is not seen as a text in the traditional sense of a completed manuscript, but rather as an assemblage of many culturally situated units of meaning, akin to how Michael McGee (1990) theorized text. To a much greater extent than most other texts, code requires technical expertise along with critical expertise in order to understand. There are numerous ways of approaching a piece of code, many of which have been discussed here on Play the Past. One of the most useful ways of looking at code is from a functional, algorithmic perspective. By critiquing the way that code enables and constrains certain actions, we can come to understand some of the underlying assumptions behind the a game. We can also come to understand a piece of software through the context provided by developer comments written in the source files themselves.
In this case, however, I’m interested in looking at code not as a way of understanding the piece of software of which it is a part, but rather as a way of understanding the history of those involved with its production. In this context, code provides an archaeological record of the goings on of programmers, computer hardware, and standards organizations. Some of the events that this record shows are easily discernible once you have access to the source code. For example, a quick comparison between the code for Wolfenstein 3D and the code for Quake shows a number of the changes that took place over the space of four or five years. Some of these merely reflect the way that both computer programming in general and Id’s own software had advanced over that space of time. For instance, the graphics code in Quake lacks the large blocks of assembly code that are fairly common in Wolfenstein’s rendering system. Other changes, such as the structuring of the code in Quake around Doom-style WAD files is more indicative of Id’s policy toward modding than any kind of technological advance.
While there is a great deal of information that can be gathered from the general structure and syntax of a body of source code, there are also many important details that can only be learned through a closer reading of the code. Perhaps the best example of this kind of close reading is the book 10 PRINT CHR$(205.5+RND(1)); : GOTO 10 (Montfort et al, 2012), which looks at the history, cultural significance, and legacy of a single line of code. These same approaches can be used to uncover subtle, yet significant information about the creation of any codebase.
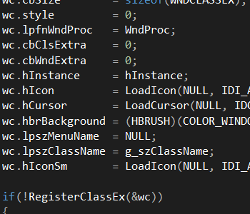
As someone who was writing software (though with varying degrees of success) for Windows in the early 2000s, I inevitably came into contact with Hungarian notation. Hungarian notation was the colloquial term for Microsoft’s variable naming conventions, which appended a number of letters to the front of every variable name in order to convey additional information about the kind of information the variable contained. The system was proposed by Charles Simonyi, Microsoft’s Chief Architect. This lead to long and impossible to pronounce variable names like hIcon, lpfnWndProc, and lpszClassName. Although it all looked the same to me at the time, Hungarian notation actually refers to two different conventions that were used by two different groups within Microsoft. Those that worked on Microsoft Word with Simonyi used a version known as Apps Hungarian, while those that programmed Windows itself created their own dialect, Systems Hungarian (Rosenberg, 2007). Thus, a programmer’s use of Hungarian notation not only shows his association with Microsoft, but what division within the company had the most influence on his coding practices.
Most coding conventions are not quite as distinct as Hungarian notation. In all their forms, however, conventions demonstrate a lineage of programming knowledge that can often be traced back to a common source. Years after abandoning C++ for the first time (a choice that was influenced in no small part by my encounters with Systems Hungarian), I began teaching myself ActionSctipt 1. At this point in time, Flash (then still a part of Macromedia) was just beginning to be seen as a viable platform for creating actual games and a number of different communities focused on Flash game development were popping up on the Internet. I managed to teach myself ActionScript (and pick up a number of bad coding habits) by reading tutorials and demo code from programmers in Australia, Estonia, and Sweden and then combining them together into a cohesive program. When I finally decided to start taking actual programming classes, I noticed that one of the other students used some of the same strange naming conventions that I used. As it turns out, he had been following some of the same tutorials that I had used to teach myself.
In addition to variable names, sometimes entire blocks of code are passed down from one generation of software to the next. For me, this meant that my collision detection contained poorly translated Estonian jokes for years to come. For companies that maintain large codebases, that code can preserve the work of programmers long after they’ve left the company. Such code is a record of these programmers’ assumptions, idiosyncrasies, and even mistakes, as in the case of the recently discovered Shellshock bug that was dutifully reproduced in the open source Bash program for over twenty years.
While the concept of code as an archaeological record certainly has implications for fields such as cybersecurity and software design, I am most interested in how it can inform the way we look at videogames and culture. In a recent article on Gamasutra, Alex Wawro spoke with the designers of Civilization: Beyond Earth, the latest game in the Civilization franchise, set to be released this week. With around twenty different games and expansions in the series, Beyond Earth is already a game with a lot of history behind it. For those who are familiar with Civilization V and its expansions, the game should feel quite familiar. The interface is largely identical, apart from swapping its Art Deco aesthetic for a more futuristic look. The mechanics of unit movement, city growth, and combat mostly carry over as well. While these similarities in themselves are somewhat interesting, the more intriguing aspects, for me at least, aren’t entirely apparent until you go deeper…

If we were to extend our archaeological metaphor to Beyond Earth, the game would look less like the Temple of Karnak, preserved in the desert, and more like the city of Rome, with its archaeological record buried beneath layer upon layer of new construction throughout millennia of constant occupation. As designer Will Miller notes, the code used for Beyond Earth doesn’t just go back to Civ V, but all the way back to the original Civilization game. He describes the code base as being very “stratified,” with one successive game being built atop the previous title. As with my previous examples, the code that Miller and his team encounter doesn’t just tell them about previous Civ titles, but about the people who helped to create them.
It’s really fascinating to go back in the Perforce history and just kind of look and see ‘Oh, here’s where Soren [Johnson] started working on it, because all the APIs are camelCase. You can go back and back and see the geology, the layers of all these previous Civilization designers’ hands in the codebase.
Miller’s co-lead designer, David McDonough, mentions that in addition to the code itself, Civilization’s source files include include comments from the original developers. These comments not only shed light on the reasoning behind the design choices in earlier Civ titles, but have also influenced the design choices for Beyond Earth. This common codebase, along with numerous other prototypes and experiments comprise an incredible archive of the history of Firaxis as a company and (in the case of the code from Civ I and II) beyond.
As impressive as the structural continuity of the Civilization codebase is, it can be easy to write it off as a special case. There are very few games that I would place in the same class as Civilization. To some extent, it might be expected that a game that has had so few changes to its core mechanic for over twenty years would have some amount of common code that runs through the series. What I find encouraging as a researcher is the fact that this kind of code longevity is not unique to huge franchises like Civ and is probably a lot more common than we normally think. Most of the people I know who work for professional game studios will attest to (or quite frequently lament) the fact that they occasionally have to work with very old code. In some cases, studios working on games for the Xbox One and PlayStation 4 still have code in their engines that was originally written when the studio was working on Super Nintendo games. This is even the case in studios that have changed ownership multiple times over the years. Although there have been massive changes in graphics, processor speeds, and general programming conventions over the last twenty years, these relics of the past live on in low-level code that is reproduced again and again.
There are two main reasons why ancient code lives on in software. In some cases, the code is just that good. A custom memory manager that was designed to squeeze every last bit of performance out of the limited hardware capacity of the Super Nintendo, in many cases, works just as well on modern consoles, even if not all of its cycle-saving tricks are strictly necessary. Old code can also be carried over into new software simply because there isn’t time to rework it properly. This is perhaps slightly more common in the crunch-prone world of videogame development than in other fields, though it certainly occurs in all large software projects. When deadlines are approaching, rewriting code that could be better tends to be low on the priority list. Although some organizations will periodically reevaluate their codebase or simply “burn everything to the ground” and start over, large software developers often don’t stop to breathe between projects.

In either case, this semi-intentional preservation of code provides a wealth of information to researchers. Unfortunately, the bigger issue from an academic perspective is the problem of access. Although I would love to be able to stand alongside Miller and McDonough as they look over bits of old code written by Sid Meier and Soren Johnson, the secretive nature of the videogame industry means that few, if any, people outside of Firaxis will ever get to see their impressive archives. This is one reason why it’s so exciting when companies like Id publicly release their old code for developers, researchers, and anyone else to look at. It’s also one of the side-benefits of games with robust modding tools, like Minecraft or Half-Life 2.
While this kind of development chronology is certainly not the only type of information that can be gathered through close readings of code, I believe it has the potential to give us a unique perspective on the games themselves. I would be curious to know how much, if any, of the code in Beyond Earth is based on (or simply inspired by) code from Alpha Centauri, which had a very different map system than most Civ games. I would like to know how concepts like what constitutes nations, barbarians, and civilized people has changed on an algorithmic level throughout the series. We don’t have access to that information today, but if companies like Firaxis continue to maintain their code archives, perhaps one day we will.
References
Julian Kücklich, (2003). Perspectives of Computer Game Philology
Michael McGee, (1990). Text, context, and the fragmentation of contemporary culture.
Nick Montfort et al, (2012). 10 PRINT CHR$(205.5+RND(1)); : GOTO 10.
Scott Rosenberg, (2007). Dreaming in Code.